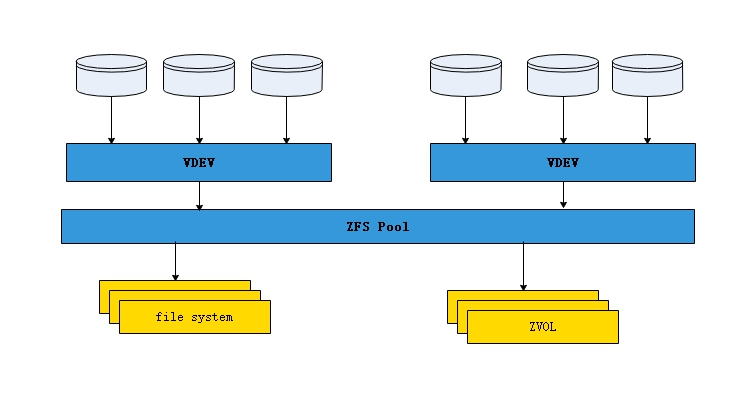
Nas数据存储:磁盘阵列raid
- 数据存储
- 2025-07-11
- 924热度
- 0评论
磁盘阵列raid是高可用方案,是预防某块(某几块)硬盘突然挂掉的方案。
1、RAID阵列模式
RAID阵列有如下几个模式:
| RAID0 | n盘组成,容量为最小盘的n倍,顺序读写速度为最慢盘的n倍,任意硬盘故障则数据全部丢失 |
| RAID1 | n盘组成,容量为最小盘的容量,顺序读写速度为最慢盘的速度,只要有一块硬盘正常工作,数据就不丢失 |
| RAID5 | n盘组成,容量为最小盘的n-1倍,顺序读速度为最慢盘的n-1倍,写速度取决于方式,故障任意一块硬盘数据不丢失,故障两块硬盘数据丢失 |
| RAID6 | n盘组成,容量为最小盘的n-2倍,顺序读速度为最慢盘的n-2倍,写速度取决于方式,故障任意一或两块硬盘数据不丢失,故障三块硬盘数据丢失 |
| RAID10 | 几对硬盘先做RAID1,几个RAID1再做RAID0 |
| RAID50 | 几块硬盘先做RAID5,几个RAID5再做RAID0 |
| RAID60 | 几块硬盘先做RAID6,几个RAID6再做RAID0 |
| JBOD | 多块硬盘首尾相连,故障某块硬盘则该硬盘数据丢失,其余硬盘数据不变 |
2、RAID阵列实现方式
2.1、硬RAID卡
LSI 926x/927x/936x、Dell H710/H730等自带缓存的阵列卡。
| 支持 | RAID0、1、5、6、10、50、60 |
| 扩容 | 以大盘换小盘(如2x1TB→2x2TB) 向阵列里添加新硬盘(如2x1TB→3x1TB) |
| 升级 | 双盘RAID1→三盘RAID5→4盘RAID6 |
| 缓存 | 板载DDR3内存颗粒(设置为Write Back时显著提高RAID5写入性能) LSI卡可选Cachecade功能,使用SATA/SAS SSD缓存 |
| 缓存 | 方案较为成熟。 可以完全不影响CPU占用,也不会受操作系统的制约 RAID5写入速度接近n-1倍单盘速度。 可使用 SSD缓存提升阵列的随机读写(Cachecade)。 |
| 缺点 | 好的阵列卡相对较贵 RAID5以上的阵列卡必须带电源,不然写入速度堪比U盘 面对硬盘的读写错误极其脆弱,必须要与支持ERC/TLER的硬盘搭配(红盘/酷狼以上) |
2.2、软RAID
没有物理raid卡,使用软件模拟,该模式下一般只推荐RAID 0、1。
- 主板芯片组
Intel主板芯片组等。支持 RAID 0、1、5、10 扩容 以大盘换小盘(如2x1TB→2x2TB)
向阵列里添加新硬盘(如2x1TB→3x1TB)升级 双盘RAID1→三盘RAID5 缓存 优点 便宜 缺点 RAID5无缓存,写入速度慢,如H170芯片组四盘RAID5写入只有25MB/s
RAID5时消耗CPU资源
RAID5无BBU(电池)保护,断电时可能故障 - madam
Linux下的软件阵列,例如Openmediavault系统自带支持 RAID0、1、5、6、10 扩容方式 以大盘换小盘(如2x1TB→2x2TB)
向阵列里添加新硬盘(如2x1TB→3x1TB)升级方式 双盘RAID1→三盘RAID5→4盘RAID6 缓存 优点 便宜
RAID5环境下写入速度也可超过100MB/s
例如3x1.5T绿盘写超100MB/s缺点 RAID5时消耗CPU资源,RAID5无BBU(电池)保护,断电时可能故障 - 群晖
实质上使用了Linux下的madam和LVM(逻辑卷管理)支持 RAID0、1、5、6、10、JBOD、SHR 扩容 以大盘换小盘(如2x1TB→2x2TB)
向阵列里添加新硬盘(如2x1TB→3x1TB)升级 双盘RAID1→三盘RAID5→4盘RAID6 缓存 高端型号可选SATA SSD缓存 优点 易于使用,开箱设置即可
RAID5环境下低端产品写入速度也可超过100MB/s,例如DS416
高端产品可使用SATA SSD缓存提升阵列的随机读写(例如DS1517+/1817+)缺点 RAID5、6无BBU(电池)保护,断电时可能故障
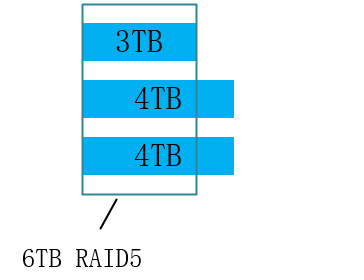
SHR的磁盘空间利用
普通RAID5,可用空间为n-1倍最小盘容量,(3-1)x2=6TB,如图
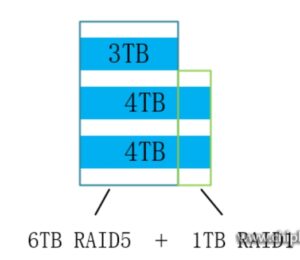
SHR,可用空间为6TB + 1TB,仍然保持了故障一盘数据不损失的特性,也利用了传统RAID不能利用的空间。
2.3、如何选择
- 硬阵列
在raid0、1模式下,可以不带电源,如果需要计算的模式,如raid5,推荐带电源。 - 软阵列
只推荐:raid0、1,会占用cpu资源,不推荐任何带计算的模式,如raid5等。 - 板载raid
只推荐:raid0、1,RAID芯片可能还是阉割或者固件不好弄, 甚至有的根本就是SATA控制器实现的软RAID。
没错说的就是你HP Microserver Gen8,除非买一些定制型的主板, 比如SuperMicro的一些存储主板, 用的RAID控制器还好点。
3、raid对硬件要求很高
对于企业用户还可以,但对个人用户不是适合的原因有下面几点
3.1、电源稳定性问题
个人家庭用户, 家里电源不会那么稳定, 小区停个电或者电卡没钱跳个闸平均一年一次是有的吧, 家里小宝宝给你乱按开关是可能的吧,而掉电是导致RAID卡里缓存的数据没有写入硬盘导致数据不一致,损坏阵列或者是导致阵列重新同步的一大原因。
3.2、普通硬盘没有应对raid机制
普通SATA盘没有适合RAID规范的低错误恢复时间功能(如LTER)。硬盘在读写数据的时候,如果偶尔某个扇区有点小问题,会反复尝试读写,这时候会失去响应几秒钟。RAID卡对于磁盘的响应时间很敏感,如果几秒内(默认15s?)某个硬盘没有回应就认为这个盘挂了,会被强制OFFLINE,这就是所谓的掉盘。企业级硬盘在尝试错误恢复的时候不会对外停止响应,会不断报告状态,我还活着,别把我踢掉。普通盘没有这个功能的,停止相应几秒钟会类似假死状态,会被raid卡踢掉。
这个技术不同厂商叫法不一样,西数的叫LTER, 希捷的叫ERC。
3.3、普通硬盘误码率太高。
普通SATA硬盘的误码率URE (Unrecoverable Read Error rate)太高。一般普通sata盘是1E-14。而企业级的SATA盘一般是1E-15。如果你用TB级别的普通SATA盘做了阵列,然后硬盘坏掉一块后,做整个阵列恢复的时候几乎是不可能的。
引述某网友的计算结果:
SATA硬盘具有 1x10^-14 次方的不可回复错误率,意思是说每100,000,000,000,000比特(11.368TB),就会有1个比特是硬盘用尽了所有的方法也读不出来的 -- 此比特是这块硬盘的黑洞。有人说,每11.368TB才出这么一个黑洞,离我们太遥远。
等等,在下“应该没问题”一类具有中国式不精确和阿Q精神的评论前我们看看如下情况:
6块2TB 消费级的硬盘组成的RAID5。假设一块硬盘掉线,一块新硬盘换上。
阵列控制器会命令剩下的5块2TB硬盘使出吃奶的劲重建阵列。5块硬盘会被从头到脚读一遍以重建冗余信息。
剩下的5块硬盘访问量有多大?
5 x 2TB = 10TB
这10TB的容量里碰到一个URE可能性有多大?
10 / 11.368 x 100% = 88%
也就是说,这样配置的RAID 5阵列在出现问题时,88%的机会是重建不了的。EMC,NETAPP等专做存储的厂商也会有自己的一些措施来提高可靠些。比如每64个4k扇区留一个做校验。所以普通人不要去玩。
3.4、RAID阵列要么铁板一块,要么全部挂掉
阵列要么是好的,要么坏了,读不出数据了,不像普通硬盘一样一个扇区坏了,只是一个文件无法读取而已。
因为RAID只做扇区级别的奇偶校验,所以整个阵列里面只要有一个扇区错误,整个raid阵列就是有问题的不可恢复的了。 哪怕这个扇区仅仅只是一个无关紧要的文件, 由于RAID是比Filesystem更底层的,所以结果就是直接出错都不能读取,而不能仅仅跳过某个文件。
4、不要轻易用RAID5
4.1、RAID5只允许挂掉一个盘
RAID 5也是以数据的校验位来保证数据的安全,但它不是以单独硬盘来存放数据的校验位,而是将数据段的校验位交互存放于各个硬盘上。这样,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。硬盘的利用率为n-1。
RAID5一次允许一个盘缺失,如果挂掉两个盘,数据就玩完了。
4.2、RAID5往往掉一个盘后,第二个盘也立刻挂掉
很多人遇到过服务器RAID5挂掉,往往掉一个盘后,第二个盘也立刻挂掉。理论上两个硬盘同时失效的概率是很低的,但为什么会这样呢?
从平均无故障时间 (MTBF)上讲,同时坏两块的概率极低:
从数学角度说,每个磁盘的平均无故障时间 (MTBF) 大约为 50 万至 150 万小时(也就是每 50~150 年发生一次硬盘损坏)。实际往往不能达到这种理想的情况,在大多数散热和机械条件下,都会造成硬盘正常工作的时间大幅减少。考虑到每个磁盘的寿命不同,阵列中的任何磁盘都可能出现问题,从统计学角度说,阵列中 N 个磁盘发生故障的机率比单个磁盘发生故障的机率要大 N 倍。结合上述因素,如果阵列中的磁盘数量合理,且这些磁盘的平均无故障时间 (MTBF) 较短,那么在磁盘阵列的预期使用寿命过程中,就很有可能发生磁盘故障(比方说每几个月或每隔几年就会发生一次故障)。
两块磁盘同时损坏的几率有多大呢(“同时”就是指一块磁盘尚未完全修复时另一块磁盘也坏掉了)?如果说 RAID 5 阵列的MTBF相当于MTBF^2,那么这种几率为每隔10^15个小时发生一次(也就是1万多年才出现一次),因此不管工作条件如何,发生这种情况的概率是极低的。从数学理论角度来说,是有这种概率,但在现实情况中我们并不用考虑这一问题。
引起硬盘坏掉往往是误码率
不过有时却是会发生两块磁盘同时损坏的情况,我们不能完全忽略这种可能性,实际两块磁盘同时损坏的原因与MTBF基本没有任何关系,而是误码率。
BER 硬盘误码率,英文是BER(Bit Error Rate),是描述硬盘性能的一个非常重要的参数,是衡量硬盘出错可能性的一个参数。
这个参数代表你写入硬盘的数据,在读取时遇到 不可修复的读错误的概率。
(不能恢复的ECC读取错误)从统计角度来说也比较少见,一般来说是指读取多少位后会出现一次读取错误。
随着硬盘容量增加,驱动器读取数据的误读率就会增加,而硬盘容量暴涨,误码率的比例一直保持相对增加。一个1TB的驱动器是需要更多读取整个驱动器,这是在RAID重建期间发生错误的概率会比300G 驱动器遇到错误的几率大。
那这个错误的几率到底有多大呢?或者说,我们写入多少GB数据,才会遇到1byte的读取错误呢?
对于不同类型的硬盘(以前企业级、服务器、数据中心级硬盘用SCSI/光纤,商用、民用级别是IDE;现在对应的则是SAS/SATA;
他们的MRBF(平均无故障时间)是接近的,但是BER便宜的SATA硬盘要比昂贵的SCSI硬盘的误码率(BER)要高得多。
也就是说,出现某个sector无法读取的情况,SATA要比SCSI严重得多。
这两种硬盘(企业级的SCSI/ FC/ SAS 磁盘)/(商用/民用级的IDE/SATA)BER的差距大概是1-2个数量级。
按照文中的计算,一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%,因此你用便宜的大容量SATA盘,在出现硬盘故障的情况下重建RAID的希望是:无法实现。
所以: 不能用大容量的家用硬盘做RAID5
数据量大到一定程度,目前来说凡是总量在2TB以上的SATA阵列,如果你做了RAID5,不仅数据没保障,万一坏掉一个盘,你有50%以上的概率同时掉第二个盘,那是一定毛都不剩一根。
我们回到RAID5的情况来。
在RAID5大行其道之初,硬盘的容量基本不超过100GB.
在过去,做RAID5一般RAID的磁盘容量都不大,比如72GB。无法恢复一个RAID的概率按照文献是1.1%(注意,1.1%已经很不错了,因为你在硬盘故障之后,才需要去恢复RAID。两个概率是要相乘的。
当硬盘容量上升到200GB,假设出现故障的概率是线性增长的[1]。那么失败率有11%,估计负责存储的人就被老板操的厉害了。
但是56%,也就是你用1TB的SATA硬盘做RAID5的话,当你遇到一个硬盘失效的情况,几乎剩下的两个以上硬盘(RAID5最少组合是3个)铁定会遇到一个硬盘读取错误,从而重建失败。
所以,以前小硬盘做RAID5,基本很少遇到同时挂掉两个盘的情况;现在硬盘大了,出问题的概率也越来越大了。
以上数据已经解释了RAID5往往一次挂两个的原因——不是用户RP问题,从BER 角度来说,是硬盘其实早坏鸟,我们没发现而已。当某个硬盘因为MTBF原因整个挂掉,有问题的BER 扇区开始跳出来作梗,于是RAID5就完蛋鸟。
我们也能总结遇到RAID5一次挂掉俩盘的概率:
-
- 使用越大容量的硬盘做RAID5,遇到BER 扇区的概率越大;比如用100G硬盘做RAID5就比用1TB的安全;
- 使用越多盘数的硬盘做RAID5,遇到BER 扇区的概率越大;比如用3个盘做的RAID5,比6个盘做的RAID5安全;
- 使用越便宜的硬盘做RAID5,遇到BER 扇区的概率越大;比如用SCSI/FC/SAS盘比用IDE/SATA的RAID5安全;
- RAID5里面存放的数据越多,塞得越满,遇到BER 扇区的概率越大;比如存了100G数据的比存了1TB数据的RAID5安全;(也要看阵列卡,某些卡REBUID时只读取存过数据的扇区,某些卡则不管三七二十一要读完整个盘。)
所以,家用NAS,做raid5的,有点傻。用绿盘做raid的,是傻的平方。
4.3、要安全,上raid1
做RAID1阵列。对于重要的、并且经常变动更新数据,比如财务数据、照片、文档资料,建议用RAID1。
RAID1多花了一个盘,但是多了一道保障。
5、要用专业的raid(NAS)盘
nas盘是用来干啥的,准确的说,要nas盘就是要tler技术,这样才适合用在nas上。
TLER=Time-Limited Error Recovery
这么说吧,普通的硬盘(不带TLER),如果读到一个数据块读不出来,就会尝试连续读取这个数据块30秒-1分钟,再读不出来,就标记这个数据块为坏道,封存再也不用。在这30秒-1分钟的尝试读取时间内,硬盘对于外界属于无响应的情况,这就是你有时候打开资源管理器却显示失去响应的原因。而大部分硬件raid阵列系统,在硬盘失去响应3-5秒后,就会判定此硬盘故障,将其从阵列中踢出去。这样的话,明明一个只是有小坏道的硬盘,却因为在30秒-1分钟的尝试时间内失去响应,被阵列踢出。重建阵列的麻烦不说,而且在重建期间如果有盘真的坏了,你的数据就悲剧了。
所以nas专用硬盘、企业级硬盘都有TLER,TLER的作用就是:当硬盘读到一个数据块读不出来,只是尝试读取3-5秒(这个时间限制可以在固件里设置的),再读不出来就立刻标记此区块为坏道,并向raid阵列报告,从其他冗余盘中读取数据重建这一小部分的阵列数据。TLER大大降低了raid阵列的掉盘率,提高了可靠性和稳定性,任何硬件nas都必须配备TLER的硬盘。
总结2句话:
- 带TLER的nas西数红盘,绝对不能用在普通桌面电脑上,包括主板自带的raid阵列上。因为桌面电脑和主板自带阵列不支持TLER,你的数据在尝试读取3秒不成功后就会被标记失败。
- 在硬件nas,比如阵列卡,或者专用集成nas(synology之类的),一定要有带TLER的硬盘。不然可靠性会大打折扣。
桌面硬盘还是NAS硬盘,主要区别是设计工作负荷:桌面级是5天*8小时,也有7天*8小时的;NAS的设计负荷是7*24的,其中希捷的明确写出8760小时每年,但仅仅说三年质保,不敢写365*24*3年。西数干脆不敢说8760每年。
企业级的设计负荷是8760小时*5年持续读写,并且不可恢复错误是10^-15,而桌面和NAS级是10^-14。
由上可见,桌面用NAS完全没问题,但是NAS比桌面级贵些,并且为了功耗NAS的性能又不如桌面级。
何必花更多的钱买更低性能的硬盘呢?
台式机的话,没必要买NAS系列,完全可以直接买ST3000DM001,7200转,7*8设计。
监控盘不适合用于桌面环境,因为监控盘的固件是针对流数据访问优化的,不适合随机访问频繁的情况。而一般的桌面和服务器应用则是需要比较大量的4K随机访问的,这也是SSD流行的主要原因。
就现在的硬盘来说,即使取消优化,或者专门优化,都不会产生特别明显的差异。
2.5寸7200转最大容量1TB,价格明显比3.5的贵啊,而且寻道和持续都没有比台式机硬盘更优秀,可以直接出局。
SV35毕竟设计初衷就不是为了台式机或服务器使用,所以也不应该考虑他。
剩下的NAS,官方文件没有体现4K随机的问题,应该和台式机类似。官方主要强调的是NAS系列专为7*24开机设计,所以同级别的NAS比桌面硬盘贵。
最后,为什么一定要买这种“稍微贵了一点”的东西呢?仅仅贵了这一点,主要是针对不同目的的优化,并没有从本质上提高。
并且,贵的这一点价格换来的是特殊需求的特性,并不是质的的提高;同时还有一定的劣势,不明白你为什么纠结于将这种非桌面硬盘用于桌面环境。
如果一定要比桌面级好的硬盘,直接上企业级,所有指标都高于桌面级,而且没有低于桌面级的指标。
我是这么理解官方文件的:官方说针对xxx优化,性能提升xxx倍——不要抱什么期望,没那么神奇;
但是如果官方说,取消xx优化,不建议用于xx环境,那么可能真的不好用。
4K随机速度和固件中的磁头调度也有很大关系的,缓存(包括阵列卡缓存)都只能在很小数据范围内提高寻道速度,因为都加载到缓存中了(比如用2GB的阵列卡寻道测试,一旦测试块超过2GB,迅速暴露硬盘的实际水平)。
所以这里所说的4K随机是全盘水平,也就是完整测试时的水平,此时缓存基本不起作用。
转速当然是关键影响因素,15K的寻道肯定比5400的寻道快。但在相同转速的盘中,固件的磁头策略对寻道的几个参数影响还是比较大的。